I am a Ph.D. student at Stevens Institute of Technology ECE department, advised by Prof. Xiaojiang Du. My research interests include IoT Security, AI for security and privacy, and LLM security.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Stevens Institute of TechnologyPh.D. in Computer EngineeringExpected May 2029
Stevens Institute of TechnologyPh.D. in Computer EngineeringExpected May 2029 -
M.Eng. in Applied Artificial IntelligenceMay 2026
-
 University of Texas at AustinM.S. in Computer ScienceAug. 2026
University of Texas at AustinM.S. in Computer ScienceAug. 2026 -
 Texas A&M UniversityB.S. in Computer Science, Minor in Mathematics & CybersecurityDec. 2023
Texas A&M UniversityB.S. in Computer Science, Minor in Mathematics & CybersecurityDec. 2023
Experience
-
 AmazonSoftware Development Engineer InternMay 2022 - Aug. 2022
AmazonSoftware Development Engineer InternMay 2022 - Aug. 2022 -
 SplunkTechnical Marketing Engineer Intern - SecurityMay 2021 - Aug. 2021
SplunkTechnical Marketing Engineer Intern - SecurityMay 2021 - Aug. 2021
Reviewing Services
-
2026TIFS ACL CVPR Workshop Anomaly Detection, Multi-Modal Reasoning for Agentic Intelligence ICLR Workshop ES-Reasoning, Reliable Agentic AI
-
2025NeurIPS D&B Track ICML Workshop World Models ICLR Workshop Representational Alignment (Re-Align), GenAI Watermarking (WMARK)
-
2024NeurIPS Workshop SafeGenAi, Behavioral ML ICML Workshop LLMs and Cognition
News
Selected as a Virtual Volunteer for ACL 2026, serving as a Virtual Session Chair and receiving a complimentary virtual registration grant.
Thrilled to receive 2nd place in the LLM for Security Competition at the NDSS 2026 LAST-X Workshop.
Passed the Google PhD SWE Intern interviews and am currently in host matching (UniqueID: 1460401482).
One paper is accepted by ICLR 2026 Lifelong Agents Workshop!
Thrilled to receive a $5,000 research grant from Tinker.
Awarded 1st place in the Stevens ECE 3MT Competition for “Making Smart Homes Smarter and Safer,” advancing to the university-level round.
I received student scholarship from WiCys 2026! See you at Washington, DC!
One paper is accepted by AAAI 2025!
I obtained Certificate in NeuroAI from Neuromatch Academy.
I graduated from Texas A&M University with B.S. of Computer Science.
Selected Publications (view all )
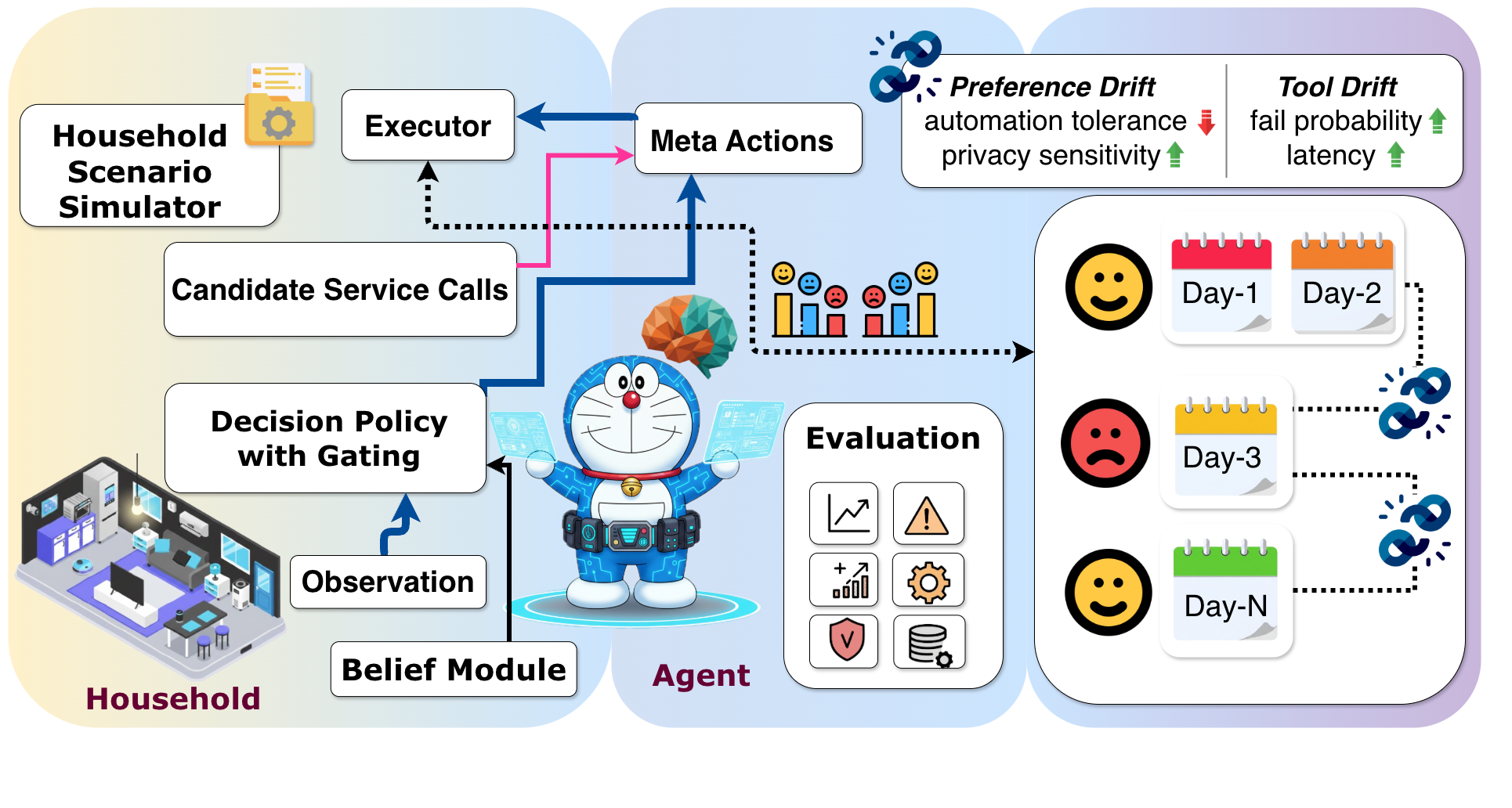
DomusMind: A Benchmark for Evaluating Lifelong Smart Home Agents Under Drift
Rong Xu, Yinxin Wan, Xiaochan Xue# (# corresponding author)
International Conference on Learning Representations Workshops on Lifelong Agents (ICLR-LLA) 2026 Workshop Poster
Smart home agents require continuous operation in non-stationary environments where human preferences and device reliability keep evolving. However, dominant evaluation protocols remain episodic and reset-based, failing to capture the degradation and recovery dynamics essential for long-term deployment. To address this gap, we introduce DomusMind, a benchmark for evaluating lifelong agents under two sources of non-stationarity: preference drift (persona) and tool drift (execution). DomusMind instantiates a persistent interaction loop where agents balance autonomous execution and user burden. By tracking time-resolved metrics across preference, tool, and mixed drift scenarios, our results show that online Theory of Mind (ToM) with uncertainty-gated confirmation provides the most robust adaptation overall. Notably, ORACLE persona access fails to mitigate tool drift, which identifies execution reliability as a distinct bottleneck. By sweeping a confirmation threshold, DomusMind characterizes a success–annoyance frontier that enables principled selection of operating points for long-horizon alignment.
DomusMind: A Benchmark for Evaluating Lifelong Smart Home Agents Under Drift
Rong Xu, Yinxin Wan, Xiaochan Xue# (# corresponding author)
International Conference on Learning Representations Workshops on Lifelong Agents (ICLR-LLA) 2026 Workshop Poster
Smart home agents require continuous operation in non-stationary environments where human preferences and device reliability keep evolving. However, dominant evaluation protocols remain episodic and reset-based, failing to capture the degradation and recovery dynamics essential for long-term deployment. To address this gap, we introduce DomusMind, a benchmark for evaluating lifelong agents under two sources of non-stationarity: preference drift (persona) and tool drift (execution). DomusMind instantiates a persistent interaction loop where agents balance autonomous execution and user burden. By tracking time-resolved metrics across preference, tool, and mixed drift scenarios, our results show that online Theory of Mind (ToM) with uncertainty-gated confirmation provides the most robust adaptation overall. Notably, ORACLE persona access fails to mitigate tool drift, which identifies execution reliability as a distinct bottleneck. By sweeping a confirmation threshold, DomusMind characterizes a success–annoyance frontier that enables principled selection of operating points for long-horizon alignment.
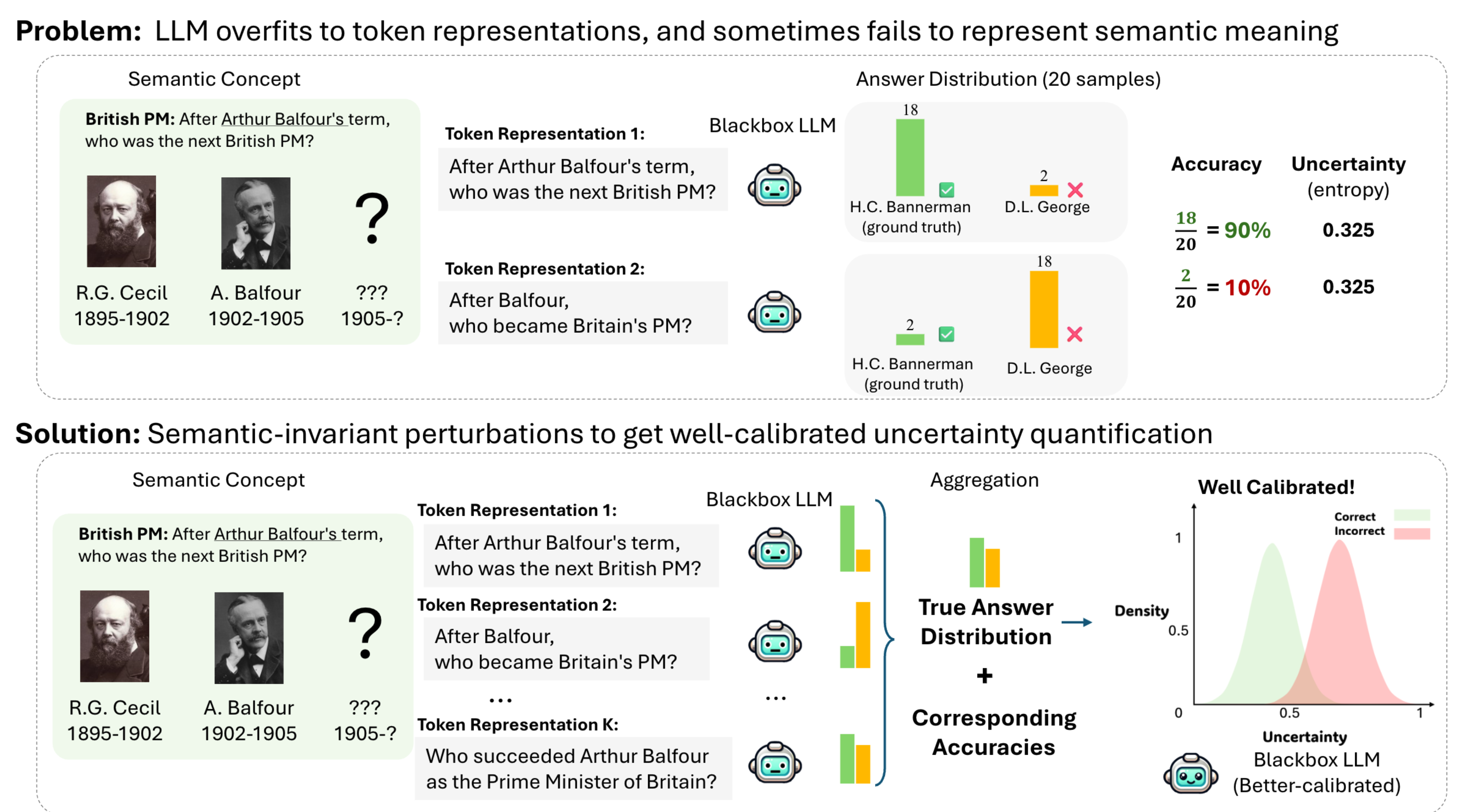
Mapping from Meaning: Addressing the Miscalibration of Prompt-Sensitive Language Models
Kyle Cox, Jiawei Xu, Yikun Han, Rong Xu, Tianhao Li, Chi-Yang Hsu, Tianlong Chen, Walter Gerych, Ying Ding# (# corresponding author)
Annual AAAI Conference on Artificial Intelligence (AAAI) 2025 Conference
An interesting behavior in large language models (LLMs) is prompt sensitivity. When provided with different but semantically equivalent versions of the same prompt, models may produce very different distributions of answers. This suggests that the uncertainty reflected in a model's output distribution for one prompt may not reflect the model's uncertainty about the meaning of the prompt. We model prompt sensitivity as a type of generalization error, and show that sampling across the semantic concept space with paraphrasing perturbations improves uncertainty calibration without compromising accuracy. Additionally, we introduce a new metric for uncertainty decomposition in black-box LLMs that improves upon entropy-based decomposition by modeling semantic continuities in natural language generation. We show that this decomposition metric can be used to quantify how much LLM uncertainty is attributed to prompt sensitivity. Our work introduces a new way to improve uncertainty calibration in prompt-sensitive language models, and provides evidence that some LLMs fail to exhibit consistent general reasoning about the meanings of their inputs.
Mapping from Meaning: Addressing the Miscalibration of Prompt-Sensitive Language Models
Kyle Cox, Jiawei Xu, Yikun Han, Rong Xu, Tianhao Li, Chi-Yang Hsu, Tianlong Chen, Walter Gerych, Ying Ding# (# corresponding author)
Annual AAAI Conference on Artificial Intelligence (AAAI) 2025 Conference
An interesting behavior in large language models (LLMs) is prompt sensitivity. When provided with different but semantically equivalent versions of the same prompt, models may produce very different distributions of answers. This suggests that the uncertainty reflected in a model's output distribution for one prompt may not reflect the model's uncertainty about the meaning of the prompt. We model prompt sensitivity as a type of generalization error, and show that sampling across the semantic concept space with paraphrasing perturbations improves uncertainty calibration without compromising accuracy. Additionally, we introduce a new metric for uncertainty decomposition in black-box LLMs that improves upon entropy-based decomposition by modeling semantic continuities in natural language generation. We show that this decomposition metric can be used to quantify how much LLM uncertainty is attributed to prompt sensitivity. Our work introduces a new way to improve uncertainty calibration in prompt-sensitive language models, and provides evidence that some LLMs fail to exhibit consistent general reasoning about the meanings of their inputs.